热点资讯
优化|DFF 框架 —— 数据有限场景下“预测 - 优化” 方法
发布日期:2025-11-21 14:27 点击次数:59
(来源:运筹OR帷幄)
文章信息
论文题目为《DFF: Decision-Focused Fine-tuning for Smarter Predict-then-Optimize with Limited Data》,发表于第39届AAAI Conference on Artificial Intelligence。文中提出了一种新颖的决策聚焦微调框架(DFF),通过嵌入偏差校正模块将决策聚焦学习(DFL)融入 PO 流程,在限定的信任区域内保持模型预测的物理意义与稳定性。本文通过网络流、投资组合优化等合成数据集实验,以及滴滴出行真实打车平台的资源分配问题验证,结果表明 DFF 不仅显著提升了决策质量,还能适配不可微预测模型,在数据有限场景下展现出强劲的适应性与可靠性。
摘要
决策聚焦学习(Decision-Focused Learning, DFL)为 “预测 - 优化”(Predict-then-Optimize, PO)框架提供了一种端到端的方法,它通过直接基于决策损失(Decision Loss, DL)训练预测模型,在PO场景下提升决策性能。然而,DFL的实际应用面临诸多独特挑战:首先,在数据有限的情况下,决策损失可能导致预测结果偏离其物理意义;其次,部分预测模型具有不可微性或属于黑箱模型,无法通过基于梯度的方法进行调整。为解决上述挑战,本文提出一种新颖的框架——决策聚焦微调(Decision-Focused Fine-tuning, DFF),该框架通过全新的偏差校正模块将DFL模块嵌入PO流程。DFF 被构建为一个带约束的优化问题,能在预设的信任区域内保持经决策损失增强后的模型与原始预测模型的接近性。本文通过理论证明,即使在数据集有限的情况下,DFF也能将预测偏差严格限制在预设上界内,从而大幅减少数据有限时由决策损失引发的预测偏移。此外,偏差校正模块可集成到各类预测模型中,增强其对广泛PO任务的适应性。在合成数据集与真实数据集(包括网络流、投资组合优化及资源分配问题,且涵盖不同预测模型)上的大量评估结果表明,DFF不仅能提升决策性能,还能满足微调约束,在各类场景下均展现出稳健的适应性。
引言
PO框架是不确定性下解决决策问题的重要方法,需先利用辅助特征预测优化问题的未知参数,再基于预测结果制定决策,但传统PO框架存在核心局限——第一阶段预测模型训练采用的MSE等损失函数仅以最小化拟合误差为目标,与最终决策任务目标可能不匹配。
为解决 PO 框架的目标不匹配问题,DFL 应运而生,它通过结合决策任务定制预测模型训练,已被证实能提升最终决策质量。然而,直接用 DFL 替代两阶段 PO 框架仍面临三大显著挑战:
收敛难题:基于决策损失(DL)从头训练模型时,因 DL 具有高度非凸性且可能不连续,下游问题梯度计算成本极高,虽可构建替代损失(如基于 Fisher 一致性),但数据有限时 DFL 仍可能收敛失败或陷入次优解;
预测偏差风险:直接最小化 DL 会导致预测结果严重偏离原始物理意义,例如线性模型场景下,DFL 的系数矩阵因依赖输入相关的半正定矩阵,会引入源于下游决策目标的偏差,可能出现乘法偏移等问题,且预测准确性难以控制;
模型适配性差:当前 DFL 训练方案多依赖一阶梯度方法,而树模型等热门预测模型不可微,同时基于物理原理的仿真模型虽能应对未观测混杂变量,但如何将 DFL 有效应用于这类不可微模型仍不明确。
基于以上问题,文章做出了如下创新:一是借助偏差校正层,DFF 能微调任意骨干模型输出以匹配决策目标;二是通过约束校正层,避免微调后输出偏离骨干模型预测的物理意义;三是从理论上分析 DFF 对微调约束的遵守性能,严格限定预测偏差;四是经合成数据集(网络流、投资组合优化)与真实数据集(滴滴资源分配)实验,证实 DFF 相较骨干模型及主流 DFL 方法,决策质量更优且适应性强。
方法
下图简要展示了所提出的决策聚焦微调(Decision-Focused Fine-Tuning, DFF)框架,在保留原始预测模型优势的基础上,通过微调优化决策性能,同时保障预测结果的物理意义与稳定性。
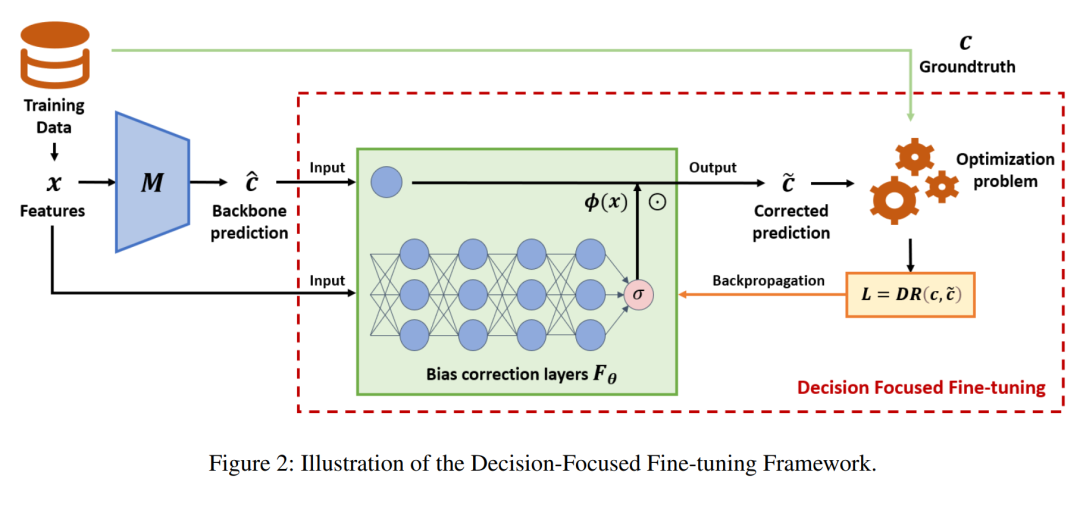
1. 约束微调
为在应用决策聚焦学习(DFL)时保留两阶段框架的优势,我们的目标是调整现有预测模型 ]article_adlist-->以实现更优的决策质量,同时确保调整后的预测结果 ]article_adlist-->与原始模型的预测结果 ]article_adlist-->保持在合理范围内。这一目标可通过如下带约束的优化(Constrained Optimization, CO)问题来表述:
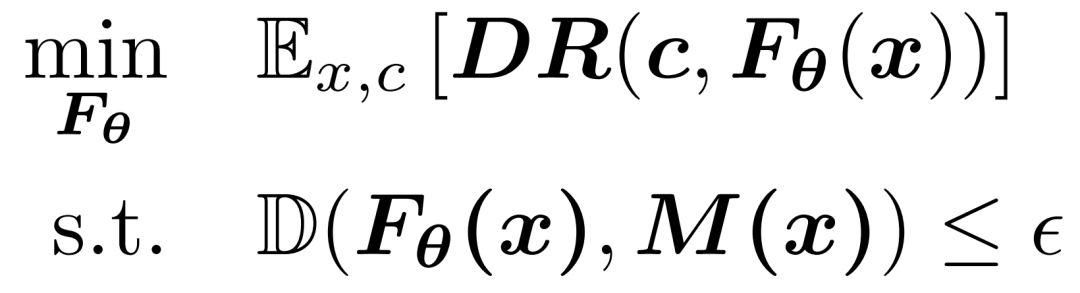
其中, ]article_adlist-->为特定场景下的距离度量(例如欧氏距离), ]article_adlist-->定义了对上游预测模型进行调整的可接受范围。该公式可理解为:在信任区域内,通过 ]article_adlist-->对上游预测模型进行微调,以提升决策性能,尤其适用于数据有限的场景。
2. 偏差校正模块
为应对“模型不可微”与“约束难实施”两大挑战挑战,文章提出了一个偏差校正模块 ]article_adlist-->。 ]article_adlist-->公式如下:
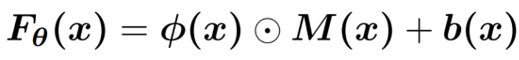
]article_adlist-->为输入依赖的权重, ]article_adlist-->为输入依赖的偏置, ]article_adlist-->是上游预测模型的输出(即原始预测 ]article_adlist-->), ]article_adlist-->为模块的所有可学习参数,最终输出为校正后的预测 ]article_adlist-->。
设置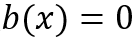 ,并对
]article_adlist-->采用偏移缩放的Sigmoid变换,公式为
,并对
]article_adlist-->采用偏移缩放的Sigmoid变换,公式为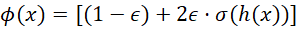 (其中
]article_adlist-->为标准Sigmoid函数,
]article_adlist-->为模块倒数第二层输出)。这一设计可确保
]article_adlist-->的输出范围严格落在
(其中
]article_adlist-->为标准Sigmoid函数,
]article_adlist-->为模块倒数第二层输出)。这一设计可确保
]article_adlist-->的输出范围严格落在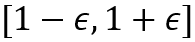 内,从数学上保障校正后预测不会偏离原始预测的物理意义。
内,从数学上保障校正后预测不会偏离原始预测的物理意义。
3. 损失函数与训练过程
确定偏差校正模块 ]article_adlist-->的约束条件后,训练过程即转化为标准的决策聚焦学习(DFL)训练流程,核心围绕损失函数定义与梯度优化如下展开。
训练采用的损失函数以 “最小化决策遗憾” 为目标,基于数据集样本的决策遗憾(DR)计算平均损失,公式如下:
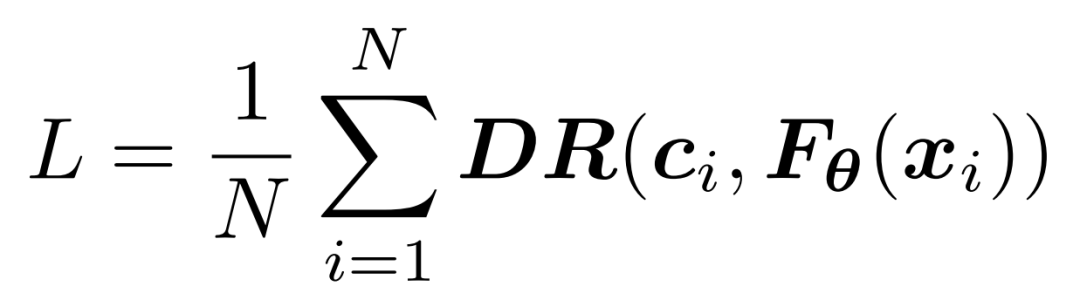
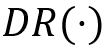 为决策遗憾(Decision Regret),用于衡量基于校正后预测的决策与基于真实参数的最优决策之间的差距,是直接关联 “预测结果” 与 “决策质量” 的核心指标。
为决策遗憾(Decision Regret),用于衡量基于校正后预测的决策与基于真实参数的最优决策之间的差距,是直接关联 “预测结果” 与 “决策质量” 的核心指标。
训练过程需解决的核心是损失函数对偏差校正模块参数 ]article_adlist-->的梯度求解问题,梯度链式法则分解如下:
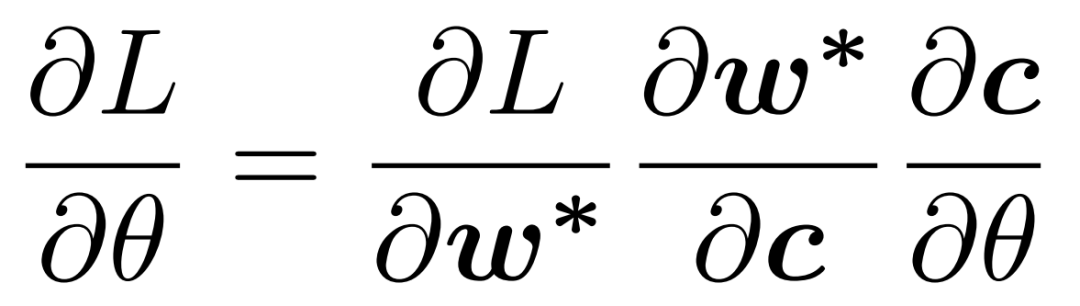
针对线性目标函数场景,采用SPO+方法直接近似计算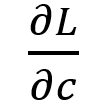 ,具体实现如下:
,具体实现如下:
构建凸上界替代损失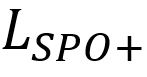 ,公式为:
,公式为:
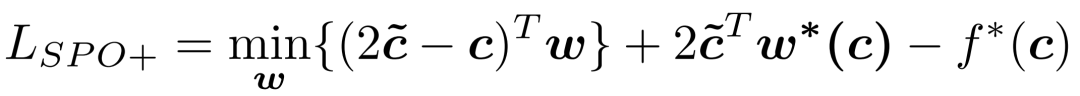
其中,
]article_adlist-->为决策变量,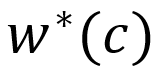 是基于真实参数的最优决策,
是基于真实参数的最优决策,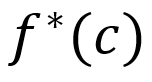 是基于真实参数的最优决策目标函数值。
是基于真实参数的最优决策目标函数值。
基于上述替代损失,可直接推导损失函数对预测参数c的梯度近似公式:
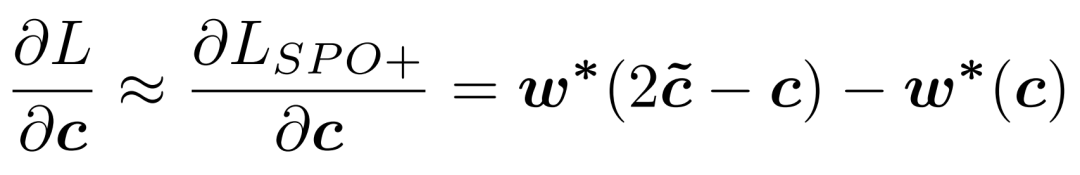
通过该式可高效计算梯度,进而完成对模块参数 ]article_adlist-->的更新,实现训练迭代。
案例研究
文章通过三类 “预测-优化”(PO)问题、多类数据集与预测模型,验证了DFF框架的有效性,所有实验均采用 10 次不同随机种子运行取平均值的方式,确保结果可靠性。
1. 基于合成数据的基准测试
选择网络流问题与投资组合优化问题两大经典 PO 任务作为基准,前者目标是最小化有流守恒约束的网络总旅行成本,后者目标是最小化资产组合负收益(含二阶锥风险约束)。
在基于合成数据的基准测试实验中,所设置的基准模型涵盖 8 类,包括以 MSE 为训练损失的基础模型(随机森林、梯度提升树、NN-MSE、2-fold Boost),以及主流决策聚焦学习(DFL)方法(SPO Forest、Dboost、NN-SPO+)。实验关键参数设置如下:树模型的最大深度统一设为 2、树数量不超过 100,神经网络采用 3 层结构(每层含 32 个神经元,激活函数为 ReLU),DFF 的约束距离参数设定为 0.5。评价指标则选用归一化决策遗憾(NDR,用于衡量决策质量,数值越小代表决策效果越优)与均方误差(MSE,用于衡量预测拟合精度)。
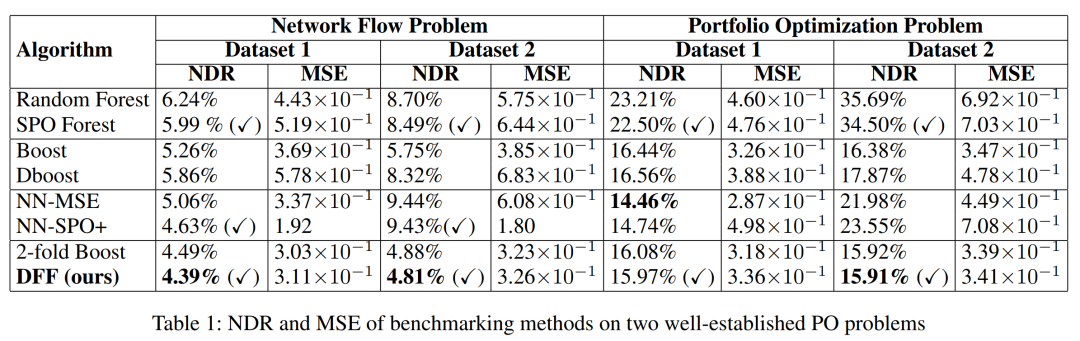
相较于SPOForest、Dboost等DFL方法,DFF在提升NDR的同时,MSE能保持与基准模型接近的水平,避免了传统DFL“为追求决策质量牺牲预测精度”的问题。
2. 基于真实数据的资源分配问题
任务为多城市打车补贴分配:基于预测的“补贴转化率”,将平台补贴预算分配给105个城市,最大化平台总收入。数据采用滴滴出行102天连续市场数据,对比模型为XGBoost、NN-SPO+。
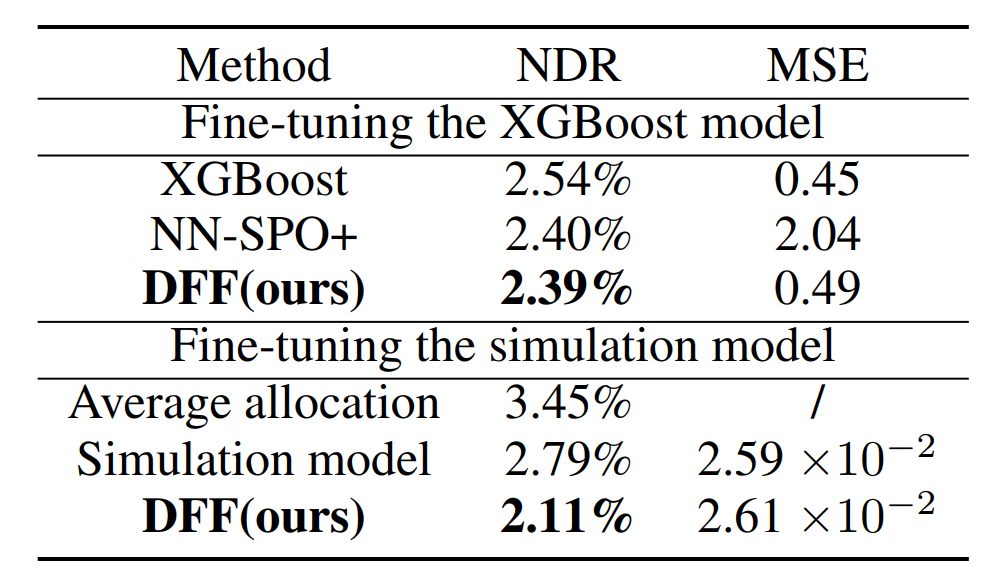
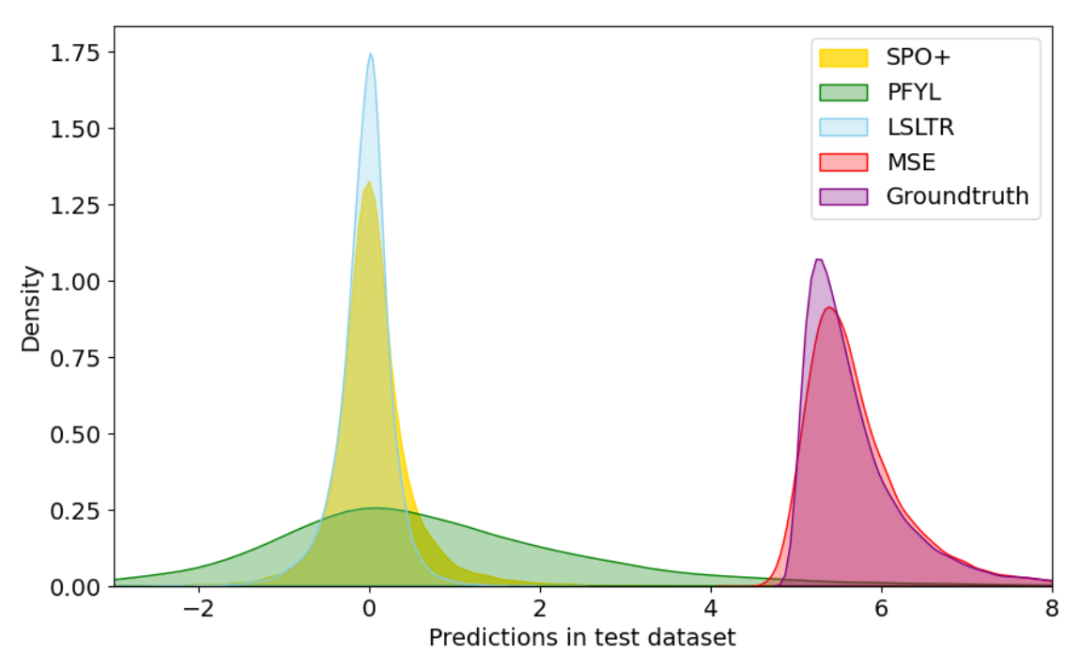
结果表明在滴滴出行真实打车平台的多城市补贴分配问题中,DFF框架的决策质量(NDR=2.39%)优于XGBoost(2.54%)与NN-SPO+(2.40%),预测稳定性(MSE=0.49)与XGBoost(0.45)接近且远优于NN-SPO+(2.04%),同时其预测分布与真实补贴转化率的“双峰分布”高度吻合,避免了NN-SPO+因受DL影响导致的预测分布偏移及物理意义丢失。
 ]article_adlist-->微信公众号后台回复
]article_adlist-->微信公众号后台回复加群:加入全球华人OR|AI|DS社区硕博微信学术群
资料:免费获得大量运筹学相关学习资料
人才库:加入运筹精英人才库,获得独家职位推荐
电子书:免费获取平台小编独家创作的优化理论、运筹实践和数据科学电子书,持续更新中ing...
加入我们:加入「运筹OR帷幄」,参与内容创作平台运营
知识星球:加入「运筹OR帷幄」数据算法社区,免费参与每周「领读计划」、「行业inTalk」、「OR会客厅」等直播活动,与数百位签约大V进行在线交流
]article_adlist-->文章须知
推文作者:ZYP
微信编辑:疑疑
文章转载自『当交通遇上机器学习』公众号,原文链接:DFF 框架 —— 数据有限场景下“预测 - 优化” 方法

FOLLOW US
]article_adlist-->

 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP